ま、面白いからといって、これで何かやろうとか考えていないのだが。
ローカル環境で数秒
当Blogでも以前にAI生成イラストをローカル環境で実施する事に挑戦した記事を書いたが、その時はプログラムが完走せずに試す事ができなかった。
だが、その後の調査で「Git」と呼ばれるStable Diffusionをクローン化するプログラムが足りない事が判明したので、そちらをネットで探してインストールしたところ、無事「Stable Diffusion UI」が完走、ローカル環境でプログラムが稼働する事を確認した。
 「Stable Diffusion UI」は使用するモデルデータが必要になるのだが、これをネットでいろいろと配布しているサイトから集め、複数のモデルを準備したのだが、今回、改めてAnythingというモデルをインストールしてみた。
「Stable Diffusion UI」は使用するモデルデータが必要になるのだが、これをネットでいろいろと配布しているサイトから集め、複数のモデルを準備したのだが、今回、改めてAnythingというモデルをインストールしてみた。
というのは、Anythingのバージョンが3から5へとアップデートされていたからだ。
Anythingは、そのバージョンによって初出が異なるという話があり、著作権の問題でいろいろ理解しておかねばならないところがあるのだが、どうも3系と5系は初出が同じという事のようなので、今回改めてAnything-v5.0を入れてみる事にした。
拡張子が最近主流の「.safetensors」となっているモデルデータだが、基本モデルデータを保存する場所は同じである。
で試しに出力してみたのだが…何か1枚あたりの画像生成時間がとんでもなく速いんだけど…。
時間にして2秒程度。
画像の大きさは512×512なので、そう大きいものではないし、プロンプトも比較的短めのものではあるのだが、それでも1枚2~3秒で出力できるというのは、ちょっと驚きだった。
なぜ速いのか?
いろいろ調べて見たら、この速さの秘密はモデルデータの拡張子が「.safetensors」に変わった、新しいタイプのものだかららしい。
もともとPythonのプログラムを実行する上でのセキュリティを考えた先に「.safetensors」というフォーマットに変わったらしいのだが、その処理速度も以前のものから比べて格段に速くなっているらしい。
「anything-v3.0」系のモデルも、現在は「.safetensors」のモデルデータに変わっているので、こちらに切替えた方がいいだろう。
私はAI生成イラストを行うには完全に後発の部類にはいるので、既に確立された手順の元で今まで蓄積されてきた恩恵をそのまま受ける形でAIイラストを生成する事になるが、後発の強みはこうした進化した形でそのシステムを導入できる事にある。
ま、それだけに仕組みや記述方式を今から入念に理解していく必要はあるし、今までの経緯を知らない事で、ちょっとした設定を知らないなんて事も多々ある。
早い時期に始めた方が良いのか、それとも後発組が良いのかは、その都度変わる話かもしれないが、私としては先人の知恵を拝借しながら、まずはその足跡を辿っていって見たいと思っている。
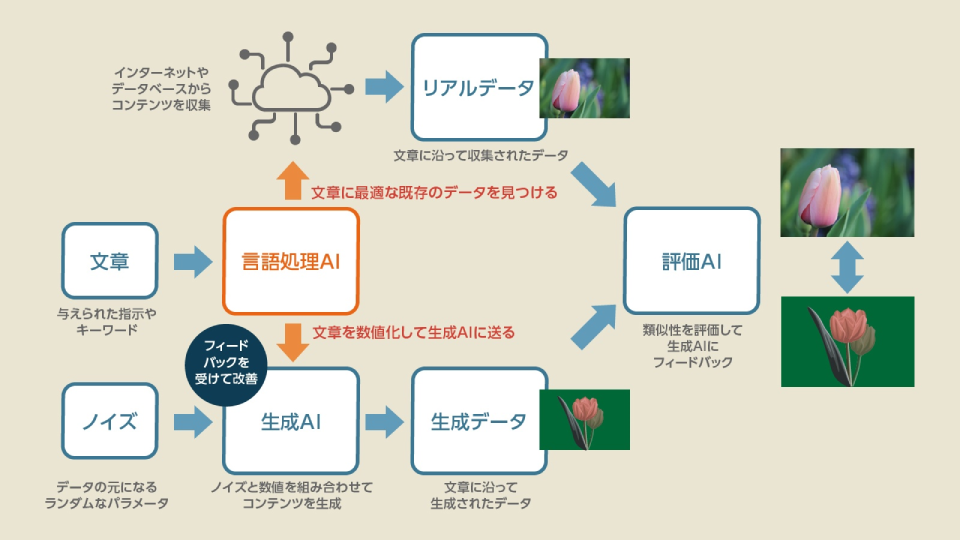 ただ、法律はこの技術的なところは見ていない。
ただ、法律はこの技術的なところは見ていない。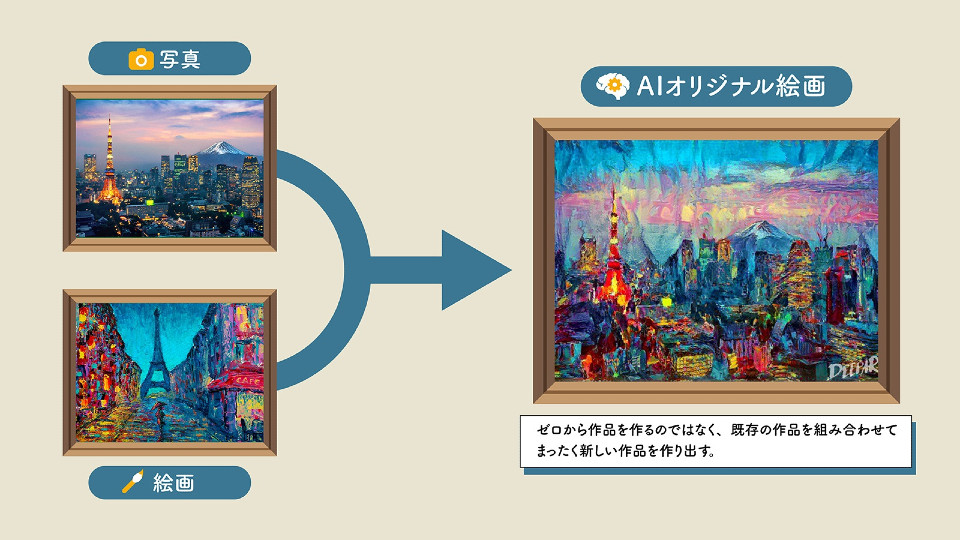














最近のコメント