Radeon RX 6000シリーズについての情報が解禁となった。性能を支える基幹技術がCPU由来というのがおもしろい。
Infinity Cache
Radeon RX 6000シリーズがライバルであるGeForce RTX 3080と性能が拮抗していると言われている所以は、ほぼこの「Infinity Cache」と呼ばれる技術に支えられているからと考えられる。
もちろん、高速なパイプライン設計、高クロック設計、ジオメトリィ/テッセレーションの最適化なと、他の要素も含めてクロックあたりの性能を向上させた事が要因ではあるが、それらを含めて、そもそも扱うデータの移動を支えている「Infinity Cache」がその性能を大きく支えている事実を外す事はできない。
かなり前から、GPUはそのGPU単体の処理性能よりも演算結果をやりとりするメモリ帯域にボトルネックがあると言われてきた。
単純にメモリ帯域を増やすと、メモリとGPUとの間のピン数を増やす必要から、基板配線が煩雑になり製造上のネックが高くなるばかりか、価格も高騰する。だからメモリクロックを高速化する、という手段に出たりもするが、そうなれば今度は発熱処理の問題も出てくるし、そもそも高速なメモリの価格は高い。
結局コストを考え、考えられるリスクを小さくしようとすると、このメモリ帯域のボトルネックを解決する方法というのは、実に難しい問題になるのだが、AMDは今回、GPUに内包するキャッシュに注目した。
キャッシュはGPU内部にあるため、レイテンシは小さく、データ移動にかかる熱量も小さくて済む。唯一の問題は、キャッシュメモリはDRAMではなくSRAMが一般的で、このSRAMは容量がその密度の関係から小さいのが問題である。DRAMなら64MB実装できても、SRAMなら4MBしかない、なんて事はよくある事である。
そこでAMDはRyzenで採用したL3キャッシュの技術に着目した。Infinity Fabricと呼ばれるラインでGPUと接続し、GDDR6の4倍ものピーク帯域性能を実現し、256bitで接続したGDDR6メモリと比較して2.4倍以上の電力あたりの性能を実現するに至った。
 これがRadeon RX 6000シリーズのメモリが256bitという帯域に留まっている最大の理由で、キャッシュデータとのやり取りを頻繁に行い、データヒット率を上げてGPUそのもののレイテンシを小さくして性能を稼いでいる、という事である。
これがRadeon RX 6000シリーズのメモリが256bitという帯域に留まっている最大の理由で、キャッシュデータとのやり取りを頻繁に行い、データヒット率を上げてGPUそのもののレイテンシを小さくして性能を稼いでいる、という事である。
Apple Silicon M1と同じ方向性
このキャッシュメモリのヒット率を上げて広帯域のメモリアクセスを取り入れるという方法は、実はApple SiliconのM1と方向性は同じである。
ただ、Apple Silicon M1の場合は、SoCにそのままメモリを内包したので、キャッシュという概念ではない、という事で、とにかくメモリアクセスを高速化する事で性能を稼ぐという方向では同じという意味である。
プロセッサの演算能力を高めるという事はもちろん重要な事ではあるのだが、ここ最近の性能向上のカギは、そのほとんどがメモリアクセスにあると考えて良いと私は思っている。
それぐらい大きなデータを入れたり出したりしているのが今の演算であり、それらをいかに省電力で、スムーズに処理できるかで、システム全体のパフォーマンスを左右するケースが多い。
NVIDIAも、このメモリアクセスの高速化という所に何も手を入れていないわけではないのだが、AMDはCPUでその技術を確立し、それをGPUに展開したというところで、一歩先んじた結果が、今回のRadeon RX 6000シリーズという事である。
ダイサイズがライバルよりも小さい事から、比較的価格は安く抑えられているのがポイントだが、何より、電力効率を54%も引き上げたこの性能向上こそ、Radeon RX 6000シリーズの本懐ではないかと思う。
 例えば、AMDのRenoir、Ryzen7 4750Gを搭載したミニPCを自作したとしたら、少なくともMac miniよりも高く付くし、その性能にしてもApple Silicon「M1」を搭載したMac miniの方が上回るだろうと思われる。しかもMac miniはOSが標準で付いてくるし、そのOSの中にはかなり有用なアプリケーションが多数付いてくる事を考えると、実にお買い得である。
例えば、AMDのRenoir、Ryzen7 4750Gを搭載したミニPCを自作したとしたら、少なくともMac miniよりも高く付くし、その性能にしてもApple Silicon「M1」を搭載したMac miniの方が上回るだろうと思われる。しかもMac miniはOSが標準で付いてくるし、そのOSの中にはかなり有用なアプリケーションが多数付いてくる事を考えると、実にお買い得である。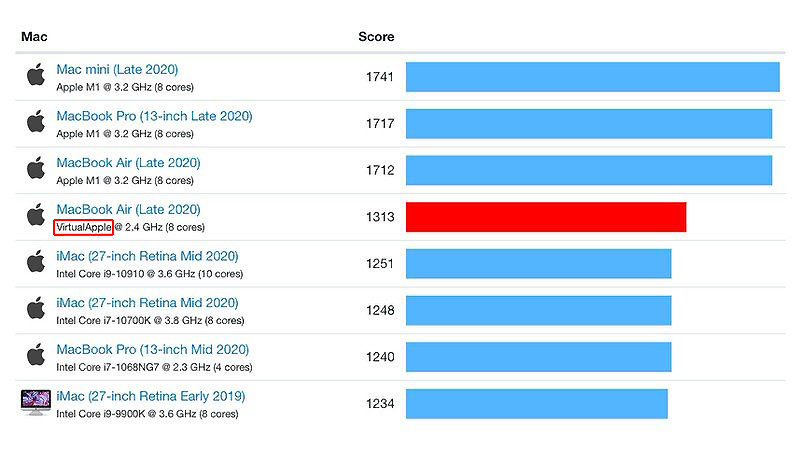 8GB RAMのM1搭載MacBook Airのスコアらしいが、シングルスコアで1,313、マルチコアスコアで5,888となっており、ARMネイティブコードでの実行結果の大凡78~79%のパフォーマンスを持っているらしい事が判明した。
8GB RAMのM1搭載MacBook Airのスコアらしいが、シングルスコアで1,313、マルチコアスコアで5,888となっており、ARMネイティブコードでの実行結果の大凡78~79%のパフォーマンスを持っているらしい事が判明した。 今回の「macOS Big Sur」は、ネットで情報を集めた感じでは思ったほど致命的なバグは出ていないような感じだが、おそらくこれはまだ人柱が足りていないのだろうと思う。
今回の「macOS Big Sur」は、ネットで情報を集めた感じでは思ったほど致命的なバグは出ていないような感じだが、おそらくこれはまだ人柱が足りていないのだろうと思う。 別に、他に何かツールを埋め込んだりしているかといえば、Google系のコードを埋め込んだりはしているけれど、Amazonのリンクに関わるものなど何もないし、意味がわからない。
別に、他に何かツールを埋め込んだりしているかといえば、Google系のコードを埋め込んだりはしているけれど、Amazonのリンクに関わるものなど何もないし、意味がわからない。 IntelやAMDがいかに多数のコアをまとめてキャッシュメモリにアクセスさせようとも、今回のM1ほど効率的にメモリにCPUやGPUがアクセスできるようにできた事は一度足りともない。だから少なくともメモリアクセスに起因する性能低下はM1チップでは考えにくい。
IntelやAMDがいかに多数のコアをまとめてキャッシュメモリにアクセスさせようとも、今回のM1ほど効率的にメモリにCPUやGPUがアクセスできるようにできた事は一度足りともない。だから少なくともメモリアクセスに起因する性能低下はM1チップでは考えにくい。 ポイントはDRAMまでをも統合しているという所で、今の所x86コアでここまで統合したコアを製造したメーカーは存在しない。DRAMの統合でメモリアクセスのレイテンシが極限まで小さくなれば、性能は著しく向上するのは言う迄も無い話である。
ポイントはDRAMまでをも統合しているという所で、今の所x86コアでここまで統合したコアを製造したメーカーは存在しない。DRAMの統合でメモリアクセスのレイテンシが極限まで小さくなれば、性能は著しく向上するのは言う迄も無い話である。 その後、PS4は薄型の「CUH-2000シリーズ」へと続いていき、この「CUH-2000シリーズ」の発売と共に登場したのがPS4 Proである。
その後、PS4は薄型の「CUH-2000シリーズ」へと続いていき、この「CUH-2000シリーズ」の発売と共に登場したのがPS4 Proである。 恐ろしく過激な抽選を勝ち残った人だけが購入できる状態と思うが、それは生産数が決定的に足りていないから。それでも世界のあらゆる場所で同時発売を行うのは、ライバルがその同日に発売すると発表したためであり、十分な数が揃ったから発売を開始する、という意味からはかけ離れている。
恐ろしく過激な抽選を勝ち残った人だけが購入できる状態と思うが、それは生産数が決定的に足りていないから。それでも世界のあらゆる場所で同時発売を行うのは、ライバルがその同日に発売すると発表したためであり、十分な数が揃ったから発売を開始する、という意味からはかけ離れている。 購入したデュプリケータは、ロジテックの「LHR-2BDPU3ES」という製品。12TBまでのHDDを認識できるようなので、この先もまだ使っていけるだろうと思う。
購入したデュプリケータは、ロジテックの「LHR-2BDPU3ES」という製品。12TBまでのHDDを認識できるようなので、この先もまだ使っていけるだろうと思う。 特徴的なのは、負荷が高くなればなるほどRyzen 5000シリーズが有利になるという事。Singleスレッドの性能もIntelを超えている事もあってか、特に複雑な演算でその性能差が顕著に表れるという結果となった。
特徴的なのは、負荷が高くなればなるほどRyzen 5000シリーズが有利になるという事。Singleスレッドの性能もIntelを超えている事もあってか、特に複雑な演算でその性能差が顕著に表れるという結果となった。











最近のコメント